|
|
https://blog.csdn.net/xiaoganbuaiuk/article/details/145052511
论文地址:https://arxiv.org/abs/2501.02471
大型语言模型(LLMs)主要基于英文文本训练,在中文语境中常常面临偏见和不准确的问题。在传统中医(TCM)等领域,其局限性尤为明显,因为文化和临床细节至关重要,同时缺乏特定领域的数据,如类风湿性关节炎(RA)。为解决这些问题,本文介绍了专为中医定制的首个大型语言模型——横琴-RA-v1,该模型专注于诊断和治疗RA。本文还提出了HQ-GCM-RA-C1,一个综合性的RA特定数据集,它从古代中医文献、经典文本和现代临床研究中精心挑选。该数据集使横琴-RA-v1能够提供准确且具有文化敏感度的回答,有效弥补了通用模型的不足。广泛的实验表明,横琴-RA-v1的性能优于最先进的模型,甚至在一些情况下超过了中医从业者的诊断准确性。
Hengqin-RA-v1: Advanced Large Language Model for Diagnosis and Treatment of Rheumatoid Arthritis with Dataset based Traditional Chinese Medicine
https://arxiv.org/abs/2501.02471
核心速览
研究背景
研究问题:这篇文章要解决的问题是如何利用大型语言模型(LLMs)在传统中医(TCM)领域进行类风湿关节炎(RA)的诊断和治疗。现有的LLMs主要训练在英文文本上,缺乏对中文语境的理解,尤其是在医学领域,导致其在处理RA时的准确性和可靠性不足。
研究难点:该问题的研究难点包括:中文语料库的稀缺和高偏见性、缺乏专门针对RA的中文语料库、现有LLMs在处理RA任务时的局限性。
相关工作:已有的LLMs如GPT-4、MedGemini等在医学报告生成方面取得了一定的进展,但仍存在分类不精确、覆盖范围有限等问题。此外,尽管有一些针对医学领域的预训练模型,但它们在处理RA任务时仍面临挑战。
研究方法
这篇论文提出了Hengqin-RA-v1,第一个专门针对RA的TCM大型语言模型,并介绍了HQ-GCM-RA-C1,第一个专注于RA的TCM语料库。具体来说,
模型设计:Hengqin-RA-v1是在Huatuo2的基础上开发的,使用LLaMA-7B作为基础模型,并通过中国医学知识图谱(CMeKG)和GPT-3.5生成的医学指令数据进行微调,以提高其在医学领域的问答能力。
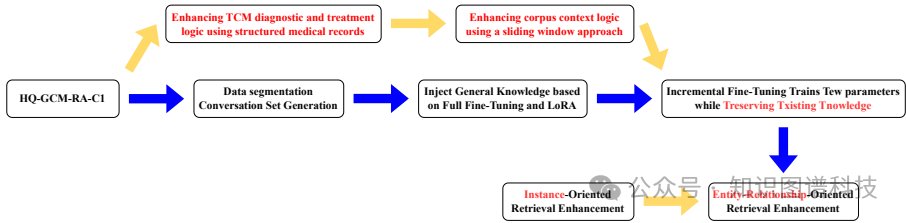
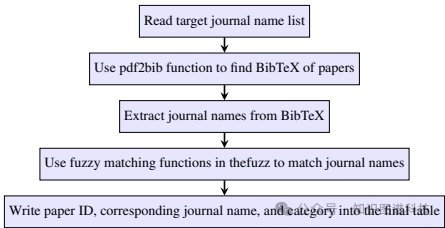
数据处理:采用五步处理流程来增强语料库上下文逻辑。首先,提取目标期刊列表并使用pdf2bib提取BibTeX条目,通过模糊匹配确保期刊名称的准确性。然后,将匹配的期刊名称、论文ID和类别编译成结构化表格,并根据期刊的重要性生成对话集。最后,采用滑动窗口方法提取“内部”和“之间”段关系,并通过添加问答对来捕捉详细的段关系。
实例增强:引入实例导向的检索增强方法,通过整合外部例子与模型生成能力,动态提供上下文和例子以提高准确性和相关性。
实验设计
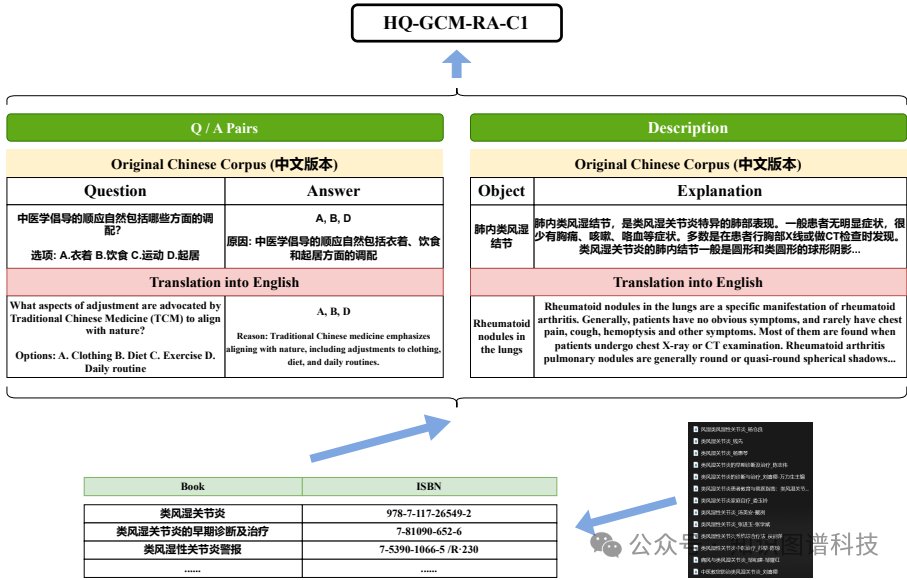
数据收集:从大量古代中医文本和近10,000篇硕士和博士论文中收集了TCM数据,包括考试问题和描述。数据格式包括问答对和多描述,来源于权威的TCM书籍、硕士和博士论文,并通过实际应用进行验证。
样本选择:数据集包括古代医书、国家级考试问题和硕士博士论文,涵盖了广泛的TCM知识和RA相关信息。
参数配置:在模型训练过程中,优先考虑知识的正确性和训练数据的规模,遵循扩展法则。采用逐步训练策略,先使用结构化病历增强TCM诊断和治疗的逻辑结构,再通过实例导向的检索增强方法保留基础模型的知识。
结果与分析
诊断建议:Hengqin-RA-v1能够总结患者症状并提供初步诊断,有效整合现代医学数据和TCM理论。例如,模型识别出湿热症状如“面色油腻黄暗”和“舌苔厚腻”,并将TCM概念如“热证”和“湿热”与实验室标志物如CRP和ALT水平联系起来。
中药推荐:推荐的中药如“柴胡”和“黄连”与湿热辨证相符,但缺乏剂量调整或配伍逻辑的明确解释,导致推荐过于宽泛和泛化。
模型性能:在TCM考试中,Hengqin-RA-v1的通过率为54%,显著优于其他中文和非中文LLMs,包括数据增强后的模型。具体来说,Baichuan的通过率为22%,ChatYuan为24%,Huatuo-2-7B为28%,其增强版为37%。非中文LLMs如GPT-2.5的通过率为18%,GPT-3.5+为37%,GPT-4为30%。
总体结论
这篇论文介绍了Hengqin-RA-v1,第一个用于RA诊断和治疗的TCM大型语言模型,并提出了HQ-GCM-RA-C1,第一个专注于RA的TCM语料库。实验结果表明,Hengqin-RA-v1在生成准确的TCM诊断和治疗建议方面表现出色,显著优于现有的中文和非中文LLMs。未来的工作将继续优化Hengqin TCM LLMs,并开发更多的TCM数据集和通用大型模型,以推动TCM智能系统的全面发展。
论文评价
优点与创新
首个针对中医领域的中文大型语言模型:Hengqin-RA-v1 是第一个专门为中医领域设计的中文大型语言模型,专注于类风湿性关节炎(RA)的诊断和治疗。
首个中医RA数据集:HQ-GCM-RA-C1 是首个专门针对中医RA的数据集,涵盖了古代中医文献、现代中医医学文献和临床研究的数据。
综合性和丰富性:该数据集包括古代书籍、国家考试题目、硕士和博士论文等,提供了丰富的RA相关文本资源。
模型性能优异:实验结果表明,Hengqin-RA-v1 在生成中医诊断和治疗文本方面优于主流大型语言模型,甚至在某些方面超过了人类专家。
结构化数据处理:提出了从原始医疗记录中提取诊断和治疗信息的数据处理流程,增强了中医诊断和治疗的逻辑结构。
实例导向的检索增强方法:通过引入外部例子,动态提供上下文和例子,提高了模型的准确性和相关性。
不足与反思
诊断方法的覆盖范围有限:当前模型在听诊和触诊方面的覆盖范围有限,忽略了关键的细节,如气味特征和脉搏信息。
中药推荐的解释不明确:推荐的中药如“柴胡”和“黄连”虽然符合湿热辨证,但缺乏剂量调整和配伍逻辑的明确解释,导致推荐过于宽泛和泛化。
语言表达的精细度不足:模型生成的语言虽然流畅,但常常缺乏中医特定的术语,降低了其精确性。
未来工作方向:计划不断优化Hengqin TCM LLMs,开发v2、v3版本以及通用的大型模型,并引入新的中医数据集,如专注于关节炎的数据集。
中文语言系统的复杂性:特别是古典中文的复杂性,即使是母语者也难以阅读和解释,同音字和多义字的普遍存在可能导致误判。
关键问题及回答
问题1:Hengqin-RA-v1在处理RA诊断和治疗时,如何利用结构化医疗记录来增强其逻辑结构?
Hengqin-RA-v1通过一个五步处理流程来增强TCM诊断和治疗的逻辑结构。首先,原始医疗记录被分割成多个部分,并与系统提示结合形成输入。然后,在任务阶段,输入经过特定处理,转化为目标数据格式。这个过程包括从原始数据中提取诊断和治疗信息,并将其组织成结构化的医疗记录。通过这种方式,Hengqin-RA-v1能够将单个医疗记录和多个医疗记录的逻辑链保留下来,从而实现全面的医疗记录分析。这种方法不仅提高了模型的准确性,还增强了其对复杂病例的处理能力。
问题2:HQ-GCM-RA-C1语料库的构建过程是怎样的?它在Hengqin-RA-v1的训练中起到了什么作用?
HQ-GCM-RA-C1语料库是通过从大量古代中医文本、近10,000篇硕士和博士论文中收集TCM数据构建的。具体步骤包括:提取BibTeX条目、模糊匹配期刊名称、构建结构化表格、生成对话集和应用滑动窗口方法提取上下文关系。这个语料库不仅包含了问题和答案对,还包括详细的描述性文本,从而提供了丰富的TCM知识和实践经验。在Hengqin-RA-v1的训练中,HQ-GCM-RA-C1作为训练数据,帮助模型学习到准确的TCM诊断和治疗方法。通过使用这个语料库,Hengqin-RA-v1在TCM考试中的通过率显著高于其他模型,达到了54%。
问题3:Hengqin-RA-v1在实验中表现如何?与其他中文和非中文LLMs相比有哪些优势?
在实验中,Hengqin-RA-v1在TCM考试中的通过率为54%,显著优于其他中文和非中文LLMs。具体比较显示,Baichuan的通过率为22%,ChatYuan为24%,Huatuo-2-7B为28%,而Hengqin-RA-v1则达到了54%。即使是数据增强的模型,如Huatuo-2-7B*和GPT-3.5+,也未能超越Hengqin-RA-v1的性能。这表明Hengqin-RA-v1的设计、训练方法和领域特定的优化使其在TCM相关任务中表现出色。此外,Hengqin-RA-v1还能够生成个性化的治疗计划,并有效地将现代医学数据与TCM理论相结合,显示出其在诊断和治疗方面的全面性和专业性。 |
|
 闽公网安备35010302000392号 闽ICP备06029681号-4 )
闽公网安备35010302000392号 闽ICP备06029681号-4 )